Introdução ao GlusterFS (File System)
GlusterFS
é um sistema de arquivos em cluster capaz de escalar a vários peta-bytes. Ele
agrega vários Bricks de armazenamento. Os casos de uso para GlusterFS incluem
computação em nuvem, streaming de mídia e distribuição de conteúdo. sistemas de
armazenamento com base em GlusterFS
são adequados para dados não estruturados, como arquivos de documentos,
imagens, áudio e vídeo, e arquivos de log.
O que é GlusterFS?
GlusterFS
é um sistema de arquivos distribuído e descentralizado, trata-se de um sistema
cujo principal objetivo é a escabilidade.
Basicamente,
GlusterFS agrega múltiplas unidades de armazenamento remotas em um único
volume. As unidades de armazenamento, chamadas de Bricks, são distribuídas
pela rede em um único sistema de arquivos paralelo, permitindo uma escabilidade
de milhares de bricks e vários petabytes de armazenamento.
Os clientes, que também podem ser simultaneamente servidores de dados, montam os diretórios compartilhados pelos servidores,
tendo assim acesso a uma parte ou a todo o conteúdo compartilhado.
Vantagens do GlusterFS
- Elasticidade: Adaptado ao crescimento e á redução do
tamanho dos dados
- Dimensionar Linearmente: Tem disponibilidade de
crescimento além dos petabytes.
- Simplicidade: É fácil de gerenciar e independente do
kernel durante a execução no espaço do usuário.
- Flexivel: GlusterFS é um software único de sistema de
arquivo, os dados são armazenados em sistema de arquivos nativos como ext4, xfs
etc.
- Alta disponibilidade: Os dados podem ser altamente
disponível por espelhamento síncrono em vários servidores. GeoReplication pode
ser usado para espelhamento em um centro de dados remoto.
- Open Source: Atualmente o GlusterFS é mantida pela Red
Hat Inc como parte do Red Hat Storage.
Conceitos de Armazenamento
Brick: Brick é basicamente qualquer diretório que se
destina a ser compartilhado entre o pool de armazenamento confiável.
Trusted Pool de Armazenamento: É uma coleção desses arquivos/diretórios
compartilhados.
Block Storage: São dispositivos dos quais os dados
estão sendo motivos entre os sistemas na forma de blocos.
Cluster: Dois ou mais servidores que fazem parte de um
pool de armazenamento confiável.
Distributed File System: Um sistema de arquivos no
qual os dados são distribuídos por diferentes nós, onde os usuários podem
acessar os dados sem saber a localização real do arquivo.
FUSE: É um modulo de kernel carregavel que permite aos
usua´rios criar sistemas de arquivos acima do kernel sem envolver qualquer
código do kernel.
Glusterd: glusterd é o daemon de gerenciamento do
GlusterFS.
Volume: Um volume é um conjunto lógico de 'bricks'.
Todas as operações são com base nos diferentes tipos de volumes criado pelo
usuário.
Diferentes Tipos de Volumes
- Distributed Volume:
É o tipo de volume padrão que será criado quando não
há opções especifica ao criar o volume. Em um volume distribuído, qualquer
arquivo sempre aloca em um 'brick' aleatório.

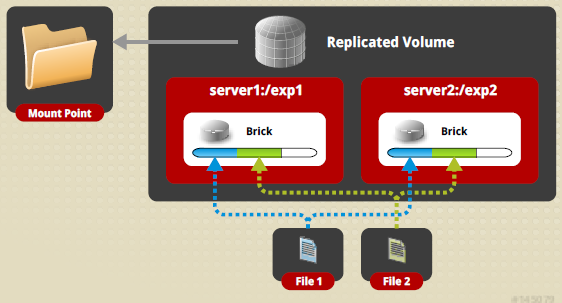
Replicated
Volume
Num volume replicado, 'bricks' são espelhados um para
o outro. Isso significa que um arquivo que está escrito em um 'brick' também
vai ser escrito para um ou mais 'bricks'. Um volume replicado é criado pela
opção "replica" durante a criação do volume.
Neste tipo de volume, os arquivos maiores são dividido
em pedaços e distribuídos pelos 'bricks'. O tamanho da faixa padrão é de
128KB, mas isso pode ser configurado para atender a necessidade de desempenho.
O volume é criado pela opção 'stripe' durante a criação do volume.

Os diferentes tipos de volumes pode ser combinados,
como por exemplo: "distributed-replicated, distributed-striped,
striped-replicated e distributed-striped-replicated"
Ao criar um volume combinado, deve-se especificar o
numero de 'bricks' múltiplos de replica. Por exemplo, ao criar 2 stripes e 3
replicas, o numero de 'bricks' deve ser múltiplo de 6 (2 x 3), significa 6
'Bricks'.

Instalação do GlusterFS no RHEL7 / CentOS7 / Fedora
Passo 1: Ambiente Necessário (Este passo não será abordado)
* Ter instalado pelo menos DOIS NODES.
* Ter configurado os hostnames "server1.example.local" e "server2.example.local"
* Conexão de rede entre os NODEs deve estar funcionando.
* Desabilitar os seguintes serviços: SELinux e FirwallD
* Ter um disco/partição adicional montado em ambos os nodes "/data/brickX/" onde X indica o numero do host, no nosso exemplo 1 e 2 respectivamente.
Passo 2: Ativar o repositorio de EPEL e GlusterFS:
Instalando o repositorio GlusterFS
# wget -P
/etc/yum.repos.d http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/glusterfs-epel.repo
Instalando o repositorio EPEL
# rpm -ivh epel-release-7-5.noarch.rpm
Passo 3: Instalando o GlusterFS
Instalar os pacotes em todos
os servidores:
# yum
install glusterfs-server
Inicie o daemon de
gerenciamento do GlusterFS em ambos os hosts.
#
systemctl start glusterd
Verifique o status do serviço
#
systemctl status glusterd
Passo 4: Configurar o "Trusted Pool"
Execute o seguinte comando somente no server1
#
gluster peer probe server2
Verifique o status
# gluster peer status

Passo 5: Configurar o Volume do GlusterFS
OBS: É
necessário ter previamente um segunda partição montada no destino: /data/brick1
e /data/brick2 dos seus respectivos servidores, não será abordado como criar e
montar novas partições.
# mkdir
/data/brick1/brick
# mkdir
/data/brick2/brick
# gluster
volume create distvol
server1:/data/brick1/brick server2:/data/brick2/brick
# gluster
volume start distvol
# gluster
volume info

Passo 6: Montando e Testando a configuração do GlusterFS
Monte o
compartilhamento do GlusterFS no próprio servidor ou em algum cliente linux.
# mount
-t glusterfs server1.example.local:/distvol /mnt
Agora
vamos criar alguns arquivos para ver como será gravado nos NODEs do
GLusterFS, lembrando que estamos usando a configuração de distributed.
# touch
/mnt/distvol-file{1..10}.txt
Ao listar o conteúdo nos NODEs teremos uma saída parecida como nas imagens abaixo:
Server1
Server2
Neste Próximo exemplo vamos criar volumes de Replica (Replicated Volume)
OBS: Vamos precisar ter uma nova partição previamente montada em "/data/brickX", onde X é referente ao respectivo server.
Passo 1: Configuração do Volume do GLusterFS
Primeiro vamos criar o diretório nos seus respectivos server's que será usado para o compartilhamento do GLusterFS.
# mkdir /data/brick3/brick
# mkdir /data/brick4/brick
Vamos criar e iniciar o volume do GlusterFS como replicated.
# gluster
volume create replvol replica 2 server1:/data/brick3/brick
server2:/data/brick4/brick

# gluster volume start replvol
# gluster volume start replvol
# gluster
volume info

Note que na imagem acima onde temos os dois volumes criados, um do tipo "Distributed" e outro do tipo "Replicate"
Recursos do GlusterFS
Geo-replication:
Fornece backup dos dados para recuperação de desastres. Aí vem o conceito de
volumes "Master" e "Slave". De modo que se o Master ficar
indisponivel, os dados podem ser acessados através de Slave. Este recurso é
usado para sincronizar dados entre servidores separados geograficamente,
Inicializar uma sessão de geo-replicação requer uma série de comandos do
Gluster.
IP
Failover: Possibilita a configuração de um IP virtual que será usado para
acessar os Nodes do Gluster, assim se um dos servidores ficar indisponível
vamos continuar tendo acesso ao compartilhamento pelo mesmo endereço de IP ao
outro servidor, tornando transparente para o usuário.
Quota: Permite limitar o tamanho de usdo de dados
armazenado dentro de um compartilhamento gluster, ou subpasta.
Snapshot:
Este recurso possibilita criar um snapshot do volume gluster e restaurar quando
e se necessário, voltando ao estado original que do momento que foi criado o
snapshot.
Estes
recursos veremos em um próximo post.
Referências: https://access.redhat.com/documentation/en-US/Red_Hat_Storage/3.1/html/Administration_Guide/index.html
Dúvidas, criticas, sugestões serão bem vindas e respondidas assim que possível.
Obrigado, até a próxima.
Nenhum comentário:
Postar um comentário